

Vous avez appris comment l’IA découpe les mots en unités (tokenisation) et comment communiquer efficacement avec elle (prompt engineering). Mais la question centrale demeure : que se passe-t-il réellement dans les microsecondes entre votre question et la réponse générée ?
Ce cours lève le voile sur les mécanismes internes qui transforment des milliards de calculs en une réponse cohérente. Nous allons explorer les concepts techniques fondamentaux qui constituent la machinerie cachée derrière l’intelligence artificielle moderne.
Partie 1 : Architecture Interne
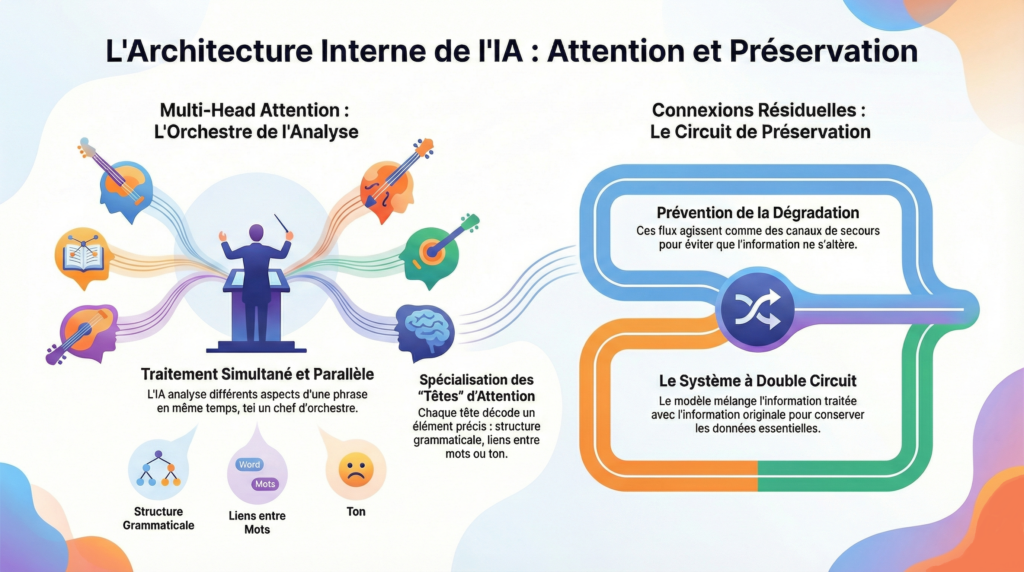
Multi Head Attention
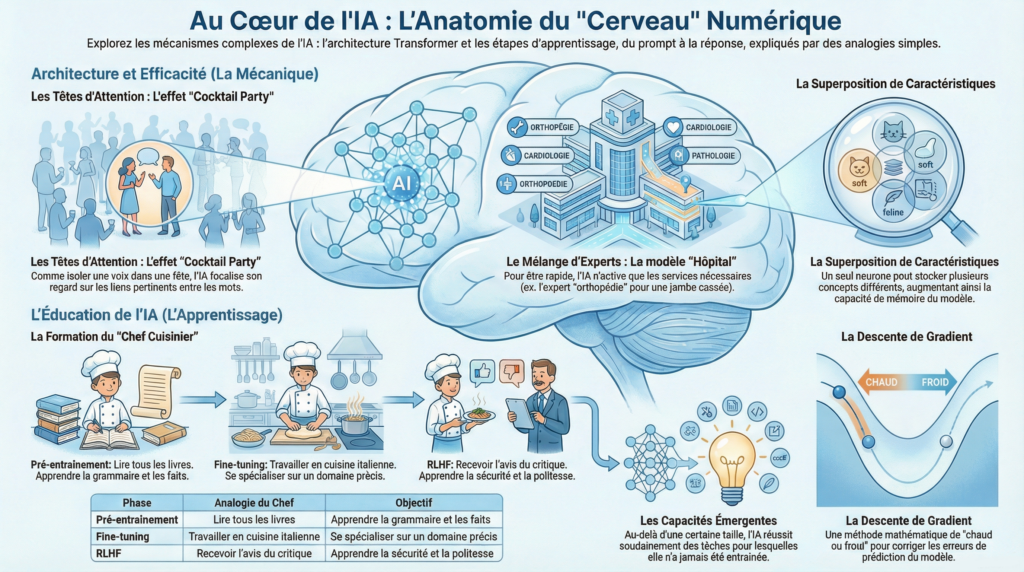
Les modèles d’IA modernes ne lisent pas le texte de manière linéaire comme un humain. Ils utilisent un mécanisme révolutionnaire appelé Multi Head Attention (Têtes d’attention multiple) qui leur permet d’analyser simultanément différents aspects d’une phrase
Analogie : L’orchestre symphonique
Imaginez un chef d’orchestre dirigeant une symphonie complexe. Pendant qu’il suit la partition principale, il doit simultanément :
- Surveiller la section des cordes pour l’harmonie générale
- Écouter les cuivres pour les accents dramatiques
- Coordonner les percussions pour le rythme
- Anticiper l’entrée du soliste
Chaque section représente une tête d’attention différente. Une tête analyse la structure grammaticale, une autre établit les liens entre pronoms et noms, une troisième décode le ton émotionnel. Toutes travaillent en parallèle pour créer une compréhension harmonieuse du texte.
Connexions Résiduelles
Dans un réseau neuronal profond comportant des centaines de couches, l’information initiale risque de se dégrader progressivement. Les flux résiduels agissent comme des canaux de préservation
Analogie : Le système d’irrigation à double circuit
Pensez à un système agricole sophistiqué où l’eau traverse de multiples stations de filtration et de traitement. Parallèlement au circuit principal qui enrichit et purifie l’eau, un canal secondaire maintient toujours une réserve d’eau originale. À chaque station, on peut mélanger l’eau traitée avec l’eau pure d’origine pour éviter de perdre les minéraux essentiels.
Les connexions résiduelles fonctionnent de la même manière : elles permettent à l’information brute de traverser directement le réseau tout en se combinant aux analyses successives.
Partie 2 : Optimisation
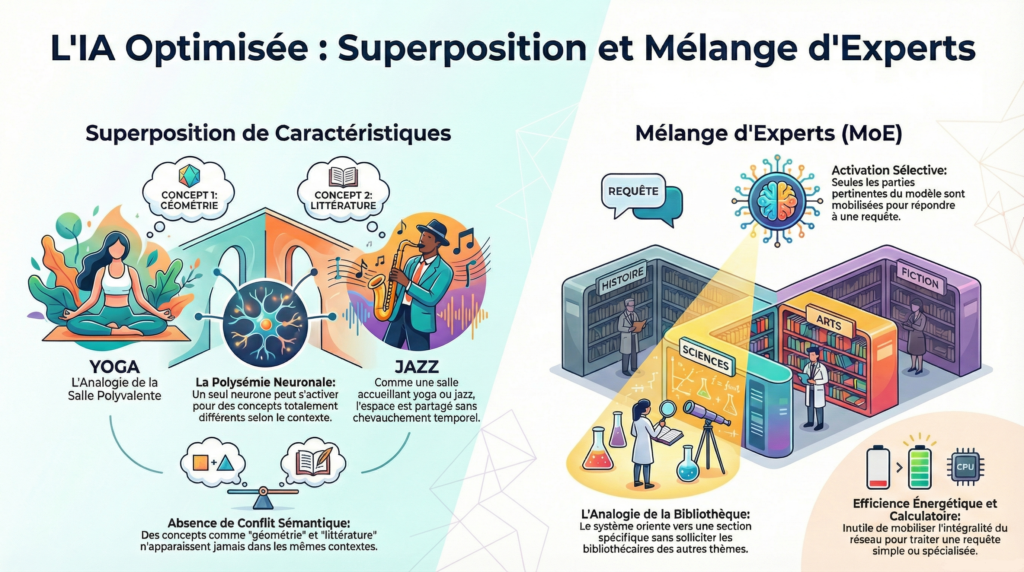
Superposition de Caractéristiques
Contrairement à ce qu’on pourrait croire, un neurone artificiel ne code pas qu’un seul concept. Ce phénomène, appelé polysémie neuronale, permet à un même neurone de s’activer pour des idées totalement différentes selon le contexte.
La salle polyvalente municipale
Une salle polyvalente peut servir :
- Le lundi matin pour les cours de yoga
- Le mercredi après-midi pour les répétitions théâtrales
- Le samedi soir pour les concerts de jazz
C’est le même espace physique, mais son « activation » correspond à des fonctions complètement différentes car ces usages ne se chevauchent jamais temporellement. Un neurone artificiel exploite cette même logique : il peut représenter « littérature française » ET « géométrie euclidienne » car ces concepts n’apparaissent jamais dans les mêmes contextes de phrase.
Mélange d’Experts
Pourquoi mobiliser l’intégralité du réseau neuronal pour traiter une simple requête ? Les architectures modernes utilisent le Mélange d’Experts (Mixture of Experts – MoE) pour activer sélectivement seulement les parties pertinentes du modèle.
Analogie : La bibliothèque universitaire spécialisée
Une grande bibliothèque universitaire possède des sections thématiques :
- Sciences exactes (mathématiques, physique)
- Sciences humaines (histoire, philosophie)
- Littérature et langues
- Droit et économie
Quand un étudiant cherche un livre sur la mécanique quantique, le système l’oriente automatiquement vers la section Sciences exactes. Les bibliothécaires des autres sections n’interviennent pas et peuvent se consacrer à d’autres visiteurs. Cette organisation permet à la bibliothèque d’être immense (couvrir tous les domaines) tout en restant efficace (mobiliser uniquement les ressources nécessaires).

Partie 3 : Apprentissage
Descente de Gradient
C’est le principe mathématique fondamental qui permet à une IA d’apprendre. Le modèle effectue une prédiction, mesure son erreur, puis ajuste ses paramètres internes pour réduire cette erreur lors de la prochaine tentative.
L’alpiniste dans le brouillard
Imaginez un alpiniste qui doit descendre d’une montagne dans un brouillard épais sans carte ni GPS. Il ne voit que quelques mètres autour de lui. Sa stratégie : à chaque pas, tâter le sol dans toutes les directions et se déplacer vers la pente la plus descendante.
Ce processus, répété des milliers de fois, le mène progressivement vers la vallée même s’il ne voit jamais la destination finale. La descente de gradient fonctionne de façon similaire : le modèle ajuste ses milliards de paramètres par petits incréments, cherchant à chaque étape la direction qui réduit le plus son erreur.
Pré-entraînement versus Ajustement Fin
L’apprentissage d’une IA se déroule en deux phases distinctes :
Pré-entraînement : Le modèle ingère des quantités massives de textes variés provenant d’internet, apprenant grammaire, faits généraux et raisonnement de base.
Fine-tuning (Ajustement fin) : On spécialise le modèle sur un domaine précis avec des données ciblées.
Analogie : La formation du musicien professionnel
- Pré-entraînement : Un jeune musicien passe des années au conservatoire. Il étudie le solfège, la théorie musicale, pratique différents styles (classique, jazz, blues), apprend plusieurs instruments. Il développe une culture musicale générale complète.
- Fine-tuning : Diplômé, il rejoint un orchestre baroque spécialisé dans Bach et Vivaldi. Il se concentre exclusivement sur le répertoire du XVIIIe siècle, perfectionne les techniques d’interprétation d’époque, mais en contrepartie, il joue moins de jazz qu’avant.
Apprentissage par Renforcement avec Retour Humain (RLHF)
Une fois que le modèle maîtrise le langage, une troisième phase intervient : le Reinforcement Learning from Human Feedback. Des évaluateurs humains notent la qualité, la pertinence et la sécurité des réponses générées.
Analogie : L’entraînement du chien guide d’aveugle
Un chien guide ne naît pas avec ses compétences :
- D’abord, il apprend les commandes de base (assis, reste, viens) – c’est le pré-entraînement
- Ensuite, il se spécialise dans le guidage en environnement urbain – c’est le fine-tuning
- Enfin, un éducateur expérimenté l’accompagne dans des situations réelles
Quand le chien s’arrête correctement à un passage piéton : récompense (renforcement positif). S’il tire trop fort sur le harnais : correction douce (signal négatif). Après des centaines d’itérations, le chien intègre non seulement les règles techniques mais aussi les comportements appropriés, la douceur et la fiabilité. C’est exactement le rôle du RLHF : affiner le comportement du modèle vers l’utilité et la sécurité.
Partie 4 : Phénomènes Avancés
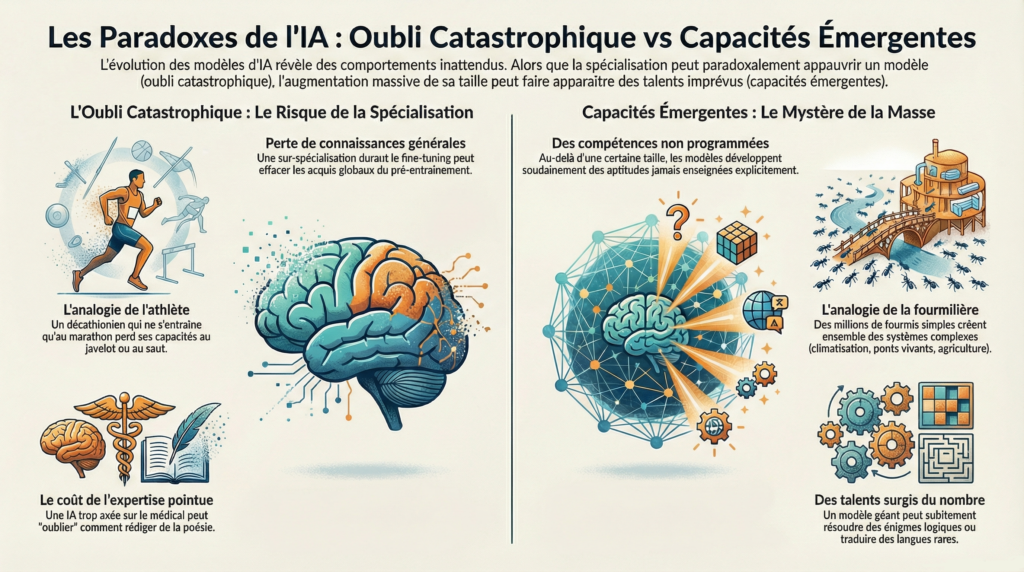
Oubli Catastrophique
Quand on sur-spécialise un modèle durant le fine-tuning, il peut perdre certaines de ses connaissances générales acquises lors du pré-entraînement. Ce phénomène est appelé oubli catastrophique.
Quand on sur-spécialise un modèle durant le fine-tuning, il peut perdre certaines de ses connaissances générales acquises lors du pré-entraînement. Ce phénomène est appelé oubli catastrophique
Analogie : L’athlète polyvalent qui se spécialise
Imaginez un décathlonien (compétition de 10 épreuves athlétiques) qui décide de se concentrer uniquement sur le marathon. Il s’entraîne exclusivement en course de fond pendant deux ans. Résultat : il devient excellent marathonien, mais il a perdu sa capacité à lancer le javelot, à sauter en hauteur ou à sprinter.
Ses muscles et sa mémoire musculaire se sont réorganisés autour d’une seule discipline, effaçant les compétences qu’il ne pratique plus. Une IA qui apprend trop spécifiquement le vocabulaire médical peut « oublier » comment rédiger de la poésie.
Capacités Émergentes
C’est l’un des mystères les plus fascinants de l’IA moderne. Au-delà d’une certaine taille (nombre de paramètres), les modèles développent soudainement des compétences pour lesquelles ils n’ont jamais été explicitement entraînés.
Analogie : La colonie de fourmis
Une fourmi individuelle est simple : elle suit des phéromones, transporte de la nourriture, obéit à des règles basiques. Mais quand vous réunissez des millions de fourmis, la colonie dans son ensemble manifeste des comportements complexes jamais « programmés » dans une fourmi individuelle :
- Construction de ponts vivants pour franchir des obstacles
- Climatisation collective de la fourmilière
- Stratégies militaires coordonnées
- Agriculture de champignons
Personne n’a enseigné à la colonie ces compétences ; elles émergent de l’interaction massive entre composants simples. De même, un modèle géant peut soudainement traduire des langues rares, résoudre des énigmes logiques ou composer dans des styles jamais vus durant l’entraînement. C’est le passage mystérieux de la quantité à la qualité.
Mise en Pratique : 3 Scénarios
1. Scénario : L’usine de montage automobile modulaire
Concept illustré : Architecture (Têtes d’Attention + Flux Résiduels)
Vous dirigez une usine de montage automobile ultra-moderne. Quand une voiture entre sur la chaîne :
- Poste A analyse la carrosserie (couleur, modèle)
- Poste B vérifie le moteur (diesel, électrique, hybride)
- Poste C contrôle l’électronique embarquée
- Poste D teste la suspension
Question : Comment l’usine peut-elle simultanément personnaliser chaque voiture tout en gardant une traçabilité complète de sa configuration d’origine ?
Réponse : Les postes A, B, C, D fonctionnent comme des têtes d’attention multiples – chacun se concentre sur un aspect différent. Parallèlement, un dossier technique (flux résiduel) suit la voiture du début à la fin, préservant toutes les spécifications initiales même après toutes les modifications.
2. Scénario : L’équipe de recherche scientifique distribuée
Concept illustré : Optimisation (Mélange d’Experts)
Un institut de recherche emploie 200 chercheurs répartis en 10 laboratoires spécialisés (génétique, climatologie, astrophysique, etc.). Quand une nouvelle question arrive (« Comment la pollution affecte-t-elle la migration des oiseaux ? »), un système automatique identifie quels 2-3 laboratoires sont pertinents.
Question : Pourquoi cette organisation est-elle plus efficace que d’avoir 200 généralistes ?
Réponse : Seuls les experts en écologie et en sciences environnementales sont mobilisés. Les astrophysiciens continuent leurs propres projets sans être interrompus. L’institut peut couvrir tous les domaines (grande capacité) tout en restant réactif (ressources ciblées). C’est exactement le principe du Mélange d’Experts.
3. Scénario : Le programme d’entraînement d’un traducteur simultané
Concept illustré : Apprentissage (Pré-entraînement, Fine-tuning, RLHF)
Marie veut devenir interprète pour les conférences de l’ONU.
Phase 1 : Elle passe 5 ans à étudier 4 langues (anglais, espagnol, chinois, arabe), lit des milliers de textes variés, développe une culture générale encyclopédique.
Phase 2 : Elle se spécialise en diplomatie internationale : vocabulaire des traités, protocoles, formulations officielles.
Phase 3 : Elle fait des simulations avec des diplomates expérimentés qui corrigent ses erreurs (« Trop littéral », « Manque de nuance », « Ton trop informel »).
Question : Que risque-t-il de se passer si Marie travaille exclusivement sur des textes médicaux pendant 2 ans après sa formation diplomatique ?
Réponse : Elle pourrait développer un « oubli catastrophique » : elle maîtrisera le vocabulaire médical mais perdra sa fluidité dans le jargon diplomatique qu’elle ne pratique plus.
Validation de Compréhension
Vous venez d’explorer les rouages internes de l’intelligence artificielle : l’architecture qui permet l’analyse parallèle (têtes d’attention, flux résiduels), les mécanismes d’optimisation (superposition, experts), les trois phases d’éducation (gradient, pré-entraînement, RLHF) et les phénomènes étranges qui émergent à grande échelle.


